简单,高效
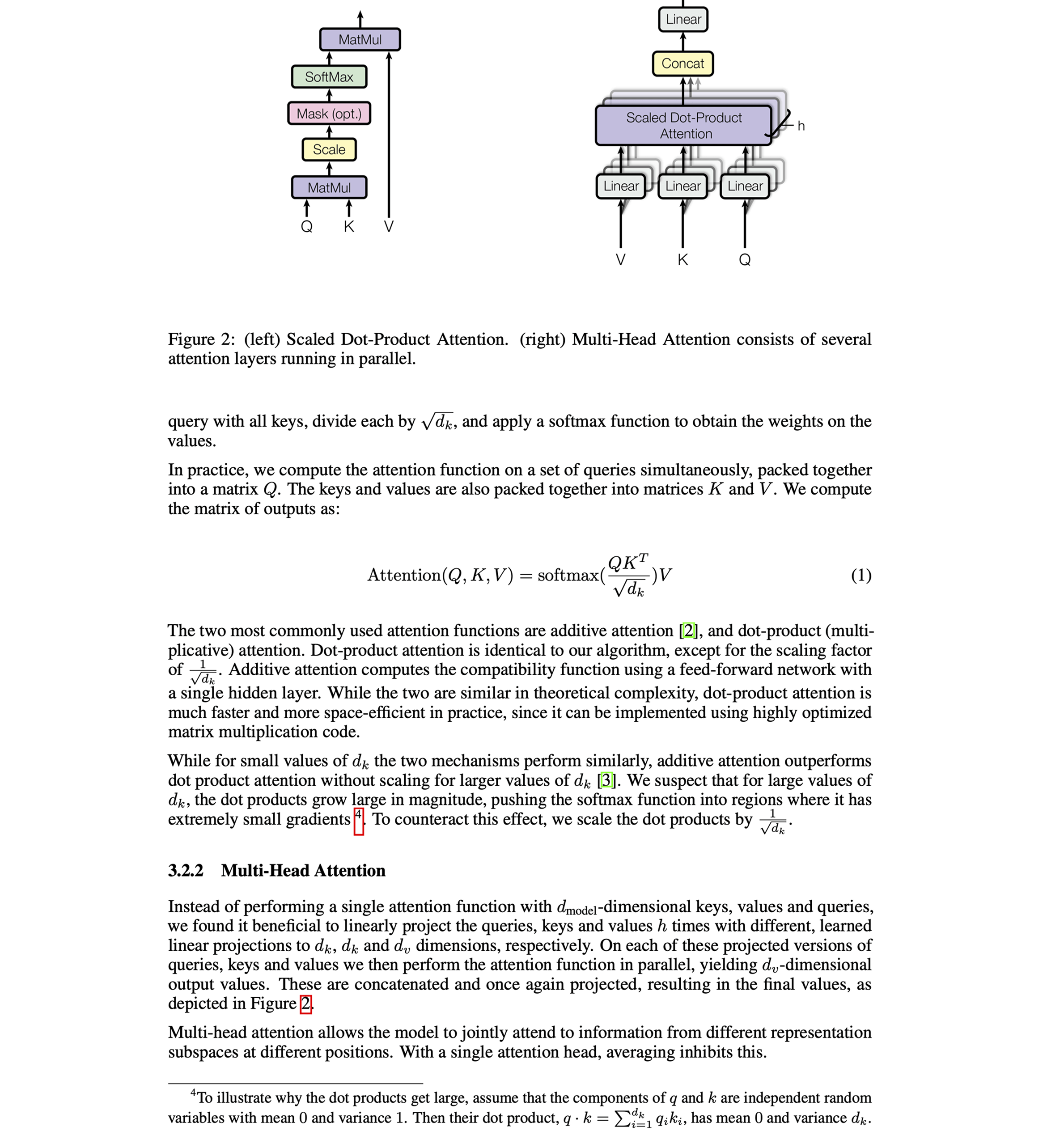
文档OCR解析工具
精确提取文档与图片中的结构化内容,适用学术论文等复杂场景,并支持大规模语料训练与知识抽取




产品优势
全格式兼容
PDF/Word/PPT/JPG等多种格式,一键处理,解决多源异构文档处理难题
立即体验

复杂元素精准抓取
深度还原跨页表格、合并单元格等复杂版面;针对学术公式进行专项优化,精准识别多行公式与生僻符号,保留文档原意
立即体验


支持批量并发处理
构建高可用并发队列,支持海量任务即时吞吐。通过智能负载均衡,保障在大数据量请求下的极速响应与零丢包
立即体验
多种格式极速输出
一键导出 Markdown/JSON/HTML 等格式,完美对接大模型知识库(RAG);公式输出为 LaTeX 标准代码,满足科研与出版级需求
立即体验
 极速处理
极速处理 主流格式支持
主流格式支持应用场景

大模型知识库构建 (RAG)
面向大模型RAG(检索增强生成)应用,将PDF、Word等非结构化文档精准清洗为Markdown或JSON格式。通过高保真保留标题层级与段落逻辑,为向量数据库提供高质量的Clean Data,显著提升大模型问答的准确率与引用溯源能力
智能学术文献解析
针对论文、教材、试卷等包含大量数学公式与特殊符号的文档,实现像素级精准还原。支持将复杂的行内公式、多行公式直接转译为 LaTeX/MathML代码,便于科研人员、师生进行二次编辑、翻译或构建数字化题库,极大缩短录入时间

金融研报数据提取
自动解析招股书、财报年报中的复杂财务表格。智能识别跨页表格、无线框表及合并单元格结构,将表格数据无损提取并导出为Excel/CSV格式。助力金融分析师快速结构化关键财务指标,实现自动化数据录入与量化分析
企业文档数字化归档
助力政府与企业实现海量纸质档案的数字化转型。支持合同、标书、发票等多种版式文档的批量OCR识别与并发处理。将扫描件与图片转化为可全文检索的双层PDF或纯文本,打通企业内部知识孤岛,提升文档流转与管理效率
